Administración de memoria.
02 JULY 2020Con el fin de entender mejor cómo se maneja la memoria se hará un breve resumen del ciclo de un programa:
- Edición: contrucción del código en un determinado lenguaje.
- Compilación: conversión del código a un lenguaje objetivo (lenguaje máquina, en general). Se revisa la consistencia del código, tipos de datos, sintaxis, etc.
- Distribución: se empaqueta el programa en un ejecutable.
- Enlace: se ligan dependencias y otras bibliotecas. El ligado puede ser estático (al compilar) o dinámico (las bibliotecas son externas).
- Ejecución.
A diferencia de Java, en C/C++ el programador participa activamente en el ciclo de vida del programa.
Sistemas operativos.
El S.O. es la primer capa de software que se carga sobre el hardware al momento de iniciar una computadora. Provee un API que abstrae los recursos y permite construir programas para el usuario final. Algunas de sus funciones son:
- Administrar los componentes e interfaces.
- Asignar procesos (CPU).
- Administrar la memoria (RAM).
- Procesar los datos.
- Manejar el disco y los archivos.
- Manejar I/O
Esquemas de manejo de memoria.
La memoria es un recurso caro por lo que debe administrarse de forma cuidadosa. De ser mal administrada, los programas “lucharán” por acaparar toda la memoria disponible. Por lo tanto, estudiaremos alguno esquemas de administración de memoria.
Esquema inexistente.
Los mainframe de antaño no tenían un esquema para la administración de la memoria. Por ejemplo la IBM 7094, una supercomputadora científica de 1960 que ofrecía una memoria de 150 kilobytes y era tan rápida como una computadora personal de los 80s.

Click aquí para aprender sobre la IBM 7094 como su aporte a la NASA
Algunas características de este esquema son:
- No había ninguna abstracción de memoria.
- Los programas están en contacto directo con la memoria física (lo cual es muy peligroso, por ejemplo un programa se carga y al no haber un esquema se corre el riesgo de que otro programa sobrecargue ciertas posiciones de memoria por lo que el primero se ve comprometido).
- Ejemplo. Al ejecutar la instrucción:
MOV AX, 1000. La computadora sólo movía el contenido de la ubicación 1000 al registro AX. - En un momento dado sólo se establece en memoria el S.O. y un solo de programa de usuario.
Cuando el S.O. ejecuta un programa, lo copia por entero a la RAM. Cuando este termina, se ejecuta otro de la misma forma. Eventualmene, este esquema soporta la multiprogramación (consiste en que varios programas puedan ejecutarse al mismo tiempo) dividiendo la memoria en bloques. Cada bloque tiene una llave (dirección de memoria única) asignada por el S.O. Si un programa trata de leer la memoria de un bloque que no le pertenece, se detiene su ejecucuión. Sim embargo, existía un problema, dado que los programas manipulaban la memoria física uno podía invadir a otro programa.
Con el fin de resolver esta situación, se introdujo static relocation. Esta consiste en que al momento de cargar el programa, las direcciones a lo interno del código se cambian sumándoles la dirección en la que se empezó a cargar.
Espacio de Direcciones (Address Spaces)
-
Cada proceso tiene un conjunto fijo de direcciones de memoria que puede utilizar.
-
Se implementa utilizando dynamic relocation. Este es un método de manejo de memoria que consiste en asignar una dirección base (relocation register) y otra límite (limit register) formando un bloque memoria física. En caso de que el consumo del proceso sea mayor al límite entonces el procesador asigna una dirección de memoria virtual e ignora la dirección física.

- Ventajas de dynamic relocation:
- El S.O. fácilmente puede reubicar un proceso.
- Los procesos tienen la libertad de crecer con el tiempo debido a que pueden ser reubicados a bloques de memoria más grandes.
- Es ejecutado por hardware y es muy sencillo en operaciones computacionales por lo que es barato y eficiente. Sólo requiere dos registros, una suma simple y una comparación simple.
- Desventajas de dynamic relocation:
- Dismuye la velocidad del hardware debido a las operaciones adicionales mencionadas.
- Los procesos no pueden compartir memoria.
- Dado que los procesos requieren de memoria fisica (sin importar su tamaño) resulta en una limitación para la multiprogramación porque cada proceso debe entrar en la memoria.
Click aquí para aprender más sobre administración de memoria y los principales métodos usados.
-
Se introduce el concepto de swapping. Si la memoria se está llenando entonces el sistema puede hacer swap y liberar toda la memoria que un proceso ocupa al guardarlo en disco. Cuando se reactiva el proceso, el sistema lo vuelve a cargar a memoria. De haber utilizado static relocation se le asigna la misma dirección que tenía. De haber utilizado dynamic relocation se le puede asignar una nueva dirección y se vuelven a definir los registros límite y base.
-
Bajo este esquema, un programa corre por cierto tiempo y de ser necesario se baja al disco y se sube otro programa en su lugar.
Memoria Virtual
“Virtual” quiere decir que se ve pero no existe. Características de este esquema:
-
El tamaño de los programas crece más del total de memoria disponible.
-
Existe una memoria virtual de mayor tamaño que la RAM. El programa opera sobre esta memoria, creyendo que en su totalidad está en la RAM.

-
El programa se divide en páginas. Cada página es un bloque de memoria contiguo.
-
La meoria real se divide en páginas. Las pagínas reales y virtuales son del mismo tamaño.
-
Cada página virtual se mapea a una página real. Este mapeo se hace mediante el MMU (Memory Management Unit) que consiste en un hardware especializado.
-
La MMU tiene la tabla de páginas. Dicha tabla mantiene el mapeo entre páginas reales y visrtuales.
-
Cuando el programa referencia una página no cargada, se dispara un page fault. Se trae la página del disco y se actualiza la tabla. Si la tabla de páginas está llena, se aplica un algoritmo de reemplazo.
De cara al programador (a nivel de proceso)
- La memoria para un proceso tiene una estructura bien definida. Esta estructura puede variar según el compilador. Para C/C++ la estructura puede ser:
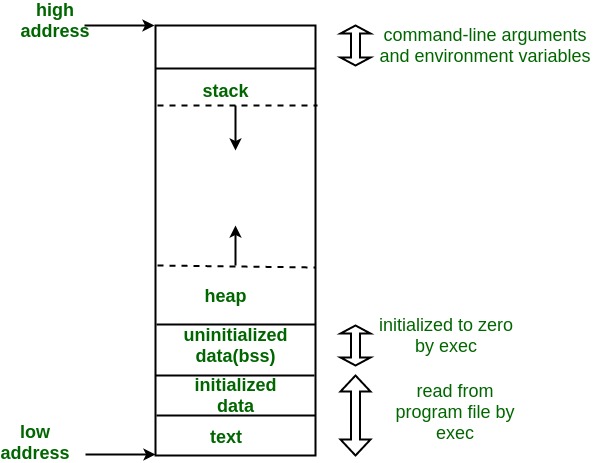
-
Text: código ejecutable.
-
Initialized data: variables globales y estáticas inicializadas por el programador.
-
Unitializeed data: variables globales no inicializadas.
-
Heap y Stack: secciones especializadas.
-
Command line arguments and environment variables: parámetros pasados al programa y variables definidas en el shell.
Stack (pila)
-
Sección del memory layout.
-
Se comporta como LIFO (last in first out).
-
Amigable para el programador debido a que se encuentran menos pulgas y requiere menos trabajo.
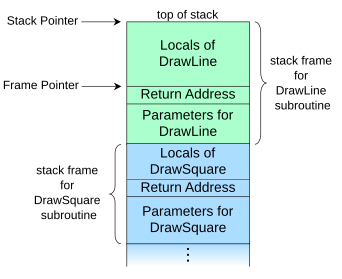
- Se compone de stack frames:
- Storage para variables locales.
- Número de línea para regresar (jmp).
- Storage para parámetros.
-
La pila hace transparente la memoria.
-
Cada llamada a un método crea un nuevo Stack Frame.
- Cuando el método termina el frame se elimina por completo y la memoria asociada se libera. Las variables locales se conoces como variables automáticas. Estas últmas sólo son de tipo primitivo.
Heap
-
Sección del memory layout.
-
No tiene estrutura.
-
No es transparente, es decir que no se maneja automáticamente.
- Tiene un API:
- malloc (memory allocation): asigna n bytes en memoria y retorna.
- free: libera la memoria apuntada por el parámetro.
- realloc.
- calloc.
- delete.
- new.
-
No impone límites a las variables usadas. Se puede hacer todo lo que quiera como estructucturas de datos más interesantes.
- En Java el Heap es manejado de manera transparente y por el garbage collector.
| Stack | Heap |
|---|---|
| Temporal. | Lifetime: control total del programador. |
| Hace copias locales. | Se tiene control sobre el tamaño de las variables. |
| El tiempo de vida es corto. | Requiere más trabajo. |
| Comunicación restringida. | Más pulgas. |
Pointer.
Consiste en un tipo de dato cuya principal función es evitar errores en runtime. Todos los punteros son del mismo tamaño según la arquitectura (32 bits -> 4 bytes, 64 bits -> 8 bytes). Existen dos principales funciones con los punteros:
- Referenciador
&: retorna la dirección de memoria en la que se ubica el puntero. - Desreferenciador
*: retorna el valor al que apunta.
Un puntero sin inicializar tiene un valor conocido como BAD VALUE. Por lo tanto, se recomienda inicializar un puntero de la forma: char *a = nullptr.
